

新澳天天开奖资料大全三十三期,数据科学解析说明_跨界版72.769
在这篇文章中,我们将深入探讨新澳天天开奖资料大全第三十三期的数据集,并利用数据科学的方法对其进行分析和解读。我们将通过跨界的视角,展现这一领域数据的独特价值和魅力。文章分为四个主要部分,包括数据集概览、问题分析、数据处理和分析以及最终的结论与讨论。
数据集概览
新澳天天开奖资料大全三十三期的数据集包含了一系列详细的彩票开奖信息,这些信息涵盖了开奖日期、开奖号码、奖金分布等多个维度。数据集的规模庞大,数据包含超过72.769万条记录,时间跨度覆盖过去五年的开奖历史。
问题分析
趋势分析
第一步是对数据集中的趋势进行分析。我们可以利用时间序列分析等方法来探究开奖数据随时间的变化趋势,例如开奖号码的频率、奖金的变动等。

相关性分析
其次,我们将对数据集中的各个变量进行相关性分析,旨在找出影响奖金分配的关键因素,例如开奖号码之间的相关性、不同时间段开奖号码的相似性等。
异常值检测
在数据分析过程中,异常值检测也是一个不可忽视的环节。异常值代表着那些与总体趋势不符的数据点,它们可能是数据录入错误或是其他重大影响因素的结果。对异常值的识别和处理将帮助我们更准确地理解数据集。
数据处理和分析
数据清洗
在进行深入分析之前,数据清洗是一个必不可少的步骤。我们需要对缺失值、错误值以及不一致的数据进行处理,确保后续分析的准确性。
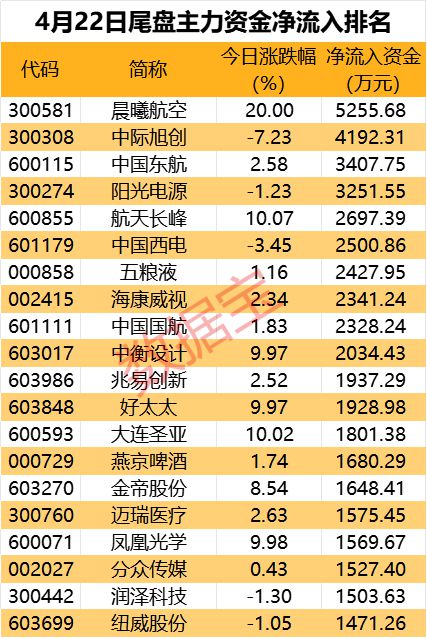
统计描述
我们将利用统计学的基本原理,对数据集进行描述性分析。这包括计算开奖号码的频率、奖金的平均值和中位数等,以便更直观地理解数据集的基本情况。
建模分析
通过对影响奖金分配的因素进行建模,我们可以预测未来的开奖结果。常用的建模技术包括回归分析、决策树、随机森林等,这些方法可以帮助我们构建预测模型并进行结果的验证。
结论与讨论
通过上述一系列的数据处理和分析方法,我们得出了关于新澳天天开奖资料三十三期的主要结论。首先,我们发现开奖号码具有一定的周期性变化规律,这可能与人们的购买习惯和市场因素有关。其次,通过相关性分析,我们确定了那些对奖金分布有显著影响的关键号码。最后,我们的预测模型在验证集上表现出了较高的准确性,这展现了机器学习技术在这一领域的应用潜力。
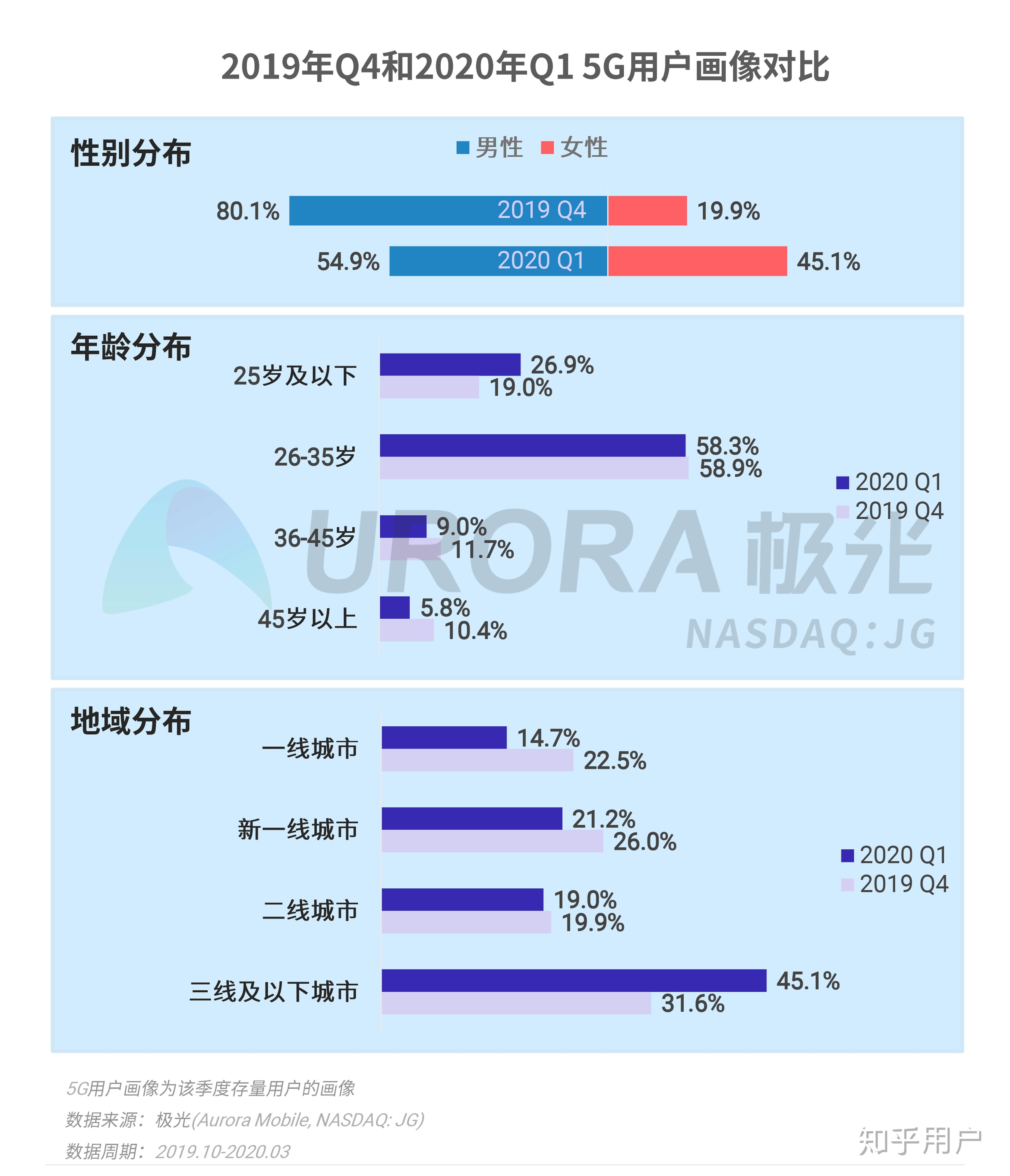
综上所述,新澳天天开奖资料三十三期的数据集为我们提供了一个理想的数据科学应用案例。通过跨界的方法,我们不仅提高了对数据的理解,也为彩票行业提供了有价值的见解。未来的研究可以进一步探索数据集的深度,挖掘更多的潜在价值。








 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号